IndoRoBERTa Financial Sentiment v2
Fine-tuned Indonesian financial sentiment classifier built on top of ihsan31415/indo-roBERTa-financial-sentiment, which itself derives from w11wo/indonesian-roberta-base-sentiment-classifier.
Model Details
| Field |
Value |
| Base Model |
ihsan31415/indo-roBERTa-financial-sentiment |
| Architecture |
RoBERTa (~125M params) |
| Language |
Indonesian (Bahasa Indonesia) |
| Task |
3-class Financial Sentiment Classification |
| License |
MIT |
| Fine-tuned on |
Google Colab T4 GPU |
Label Mapping
⚠️ Non-standard label order — inherited from the base model.
| Label ID |
Sentiment |
0 |
Positive |
1 |
Neutral |
2 |
Negative |
Training Data
This model was fine-tuned on a combination of three datasets, augmented with synthetic data:
Data Augmentation
Three augmentation methods were used to balance class distribution:
- Gemini Synthetic Generation (
gemini-2.5-flash) — Generated structured financial news sentences targeting underrepresented classes
- GPT-2 Prompt Completion (
indonesian-nlp/gpt2-medium-indonesian) — Diverse paraphrasing from financial prompt templates
- RoBERTa Masked Augmentation — Strategic token masking with protected financial keywords (tickers, directional terms)
Final Dataset Distribution
| Split |
Samples |
| Train |
20,616 |
| Test |
5,155 |
Training Configuration
TrainingArguments(
per_device_train_batch_size=64,
gradient_accumulation_steps=4,
num_train_epochs=15,
learning_rate=1e-5,
weight_decay=0.01,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
metric_for_best_model="f1",
fp16=True,
)
Training Progress
| Epoch |
Train Loss |
Val Loss |
Accuracy |
F1 |
Precision |
Recall |
| 1.0 |
0.8945 |
0.4876 |
0.7996 |
0.7998 |
0.8001 |
0.7996 |
| 2.0 |
0.4094 |
0.3435 |
0.8640 |
0.8634 |
0.8658 |
0.8640 |
| 3.0 |
0.2982 |
0.2725 |
0.8980 |
0.8979 |
0.8981 |
0.8980 |
| 4.0 |
0.2253 |
0.2469 |
0.9115 |
0.9113 |
0.9117 |
0.9115 |
| 5.0 |
0.1785 |
0.2418 |
0.9187 |
0.9186 |
0.9188 |
0.9187 |
| 6.0 |
0.1475 |
0.2384 |
0.9232 |
0.9231 |
0.9233 |
0.9232 |
| 7.0 |
0.1275 |
0.2450 |
0.9214 |
0.9213 |
0.9215 |
0.9214 |
| 8.0 |
0.1069 |
0.2452 |
0.9251 |
0.9251 |
0.9251 |
0.9251 |
| 9.0 |
0.0904 |
0.2465 |
0.9259 |
0.9258 |
0.9258 |
0.9259 |
| 10.0 |
0.0807 |
0.2460 |
0.9284 |
0.9284 |
0.9284 |
0.9284 |
| 11.0 |
0.0720 |
0.2548 |
0.9274 |
0.9273 |
0.9274 |
0.9274 |
| 12.0 |
0.0692 |
0.2570 |
0.9276 |
0.9275 |
0.9276 |
0.9276 |
| 13.0 |
0.0608 |
0.2612 |
0.9274 |
0.9273 |
0.9274 |
0.9274 |
| 13.0 |
0.0608 |
0.2460 |
0.9284 |
0.9284 |
0.9284 |
0.9284 |
Evaluation Results
| Metric |
Score |
| Accuracy |
0.9284 |
| F1 (weighted) |
0.9284 |
| Precision (weighted) |
0.9284 |
| Recall (weighted) |
0.9284 |
Per-Class Performance
| Class |
Precision |
Recall |
F1-Score |
Support |
| Positive |
0.9405 |
0.9458 |
0.9432 |
2105 |
| Neutral |
0.9110 |
0.9090 |
0.9100 |
1407 |
| Negative |
0.9278 |
0.9227 |
0.9252 |
1643 |
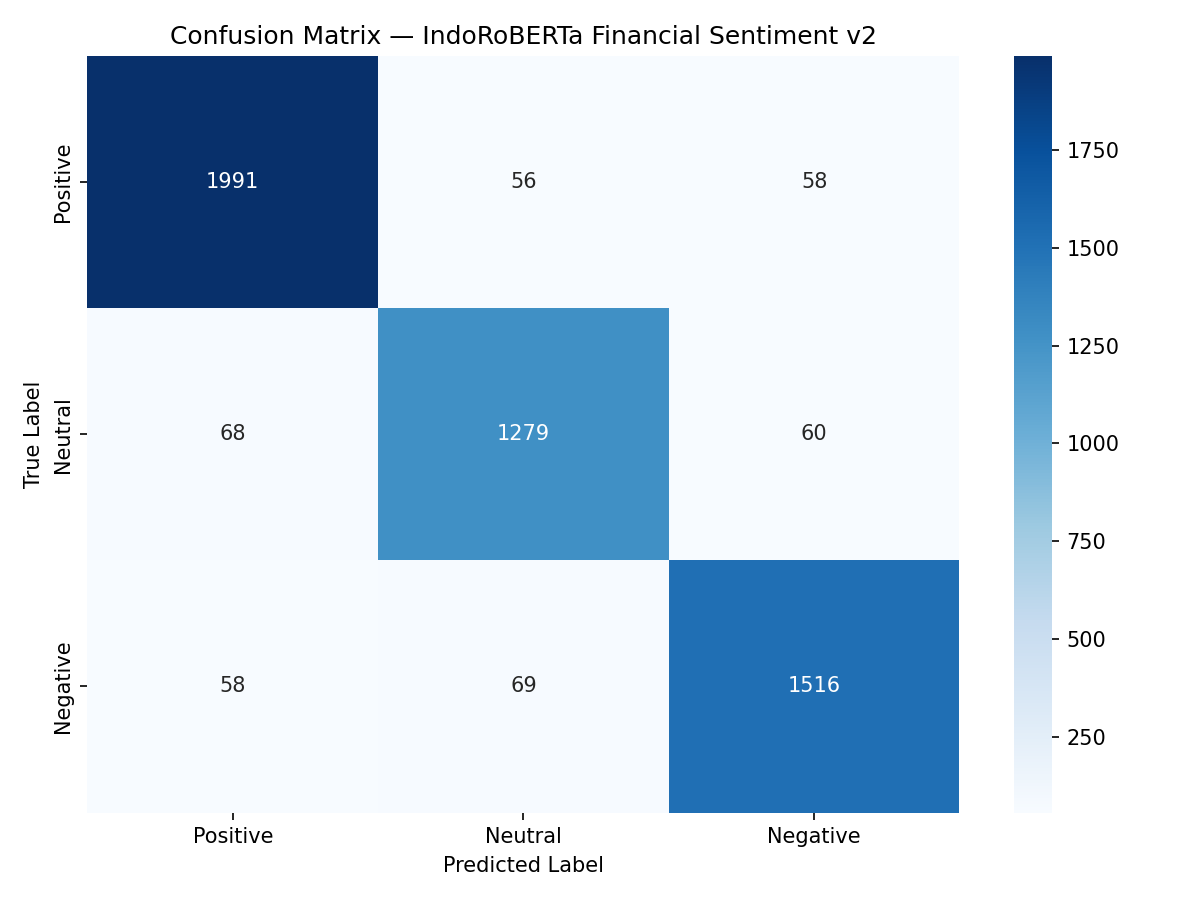
Confusion Matrix
Usage
Pipeline API
from transformers import pipeline
classifier = pipeline(
"sentiment-analysis",
model="will702/indo-roBERTa-financial-sentiment-v2"
)
result = classifier("IHSG ditutup menguat 1.5% didorong aksi beli investor asing")
Manual Inference
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained(
"will702/indo-roBERTa-financial-sentiment-v2"
)
tokenizer = AutoTokenizer.from_pretrained(
"will702/indo-roBERTa-financial-sentiment-v2"
)
text = "Rupiah melemah tajam terhadap dolar AS akibat sentimen global"
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
outputs = model(**inputs)
label_map = {0: "Positive", 1: "Neutral", 2: "Negative"}
predicted = torch.argmax(outputs.logits, dim=1).item()
print(f"Sentiment: {label_map[predicted]}")
Improvements Over Base Model
| Aspect |
Base (v1) |
This Model (v2) |
| Datasets |
1 (intanm only) |
3 (intanm + CNBC + SmSA) |
| Learning Rate |
2e-5 |
1e-5 (preserves prior knowledge) |
| Scheduler |
Linear |
Cosine with warmup |
| Primary Metric |
Accuracy |
F1 (weighted) |
| Early Stopping |
patience=2 |
patience=3 |
Limitations
- Primarily trained on formal financial news — may underperform on very informal social media text or slang
- Label mapping is non-standard (0=Positive) — ensure downstream systems account for this
- Augmented data includes synthetic samples which may not perfectly reflect real-world distribution
Citation
@misc{indo_roberta_fin_v2_2026,
title = {IndoRoBERTa Financial Sentiment v2},
author = {Gregorius Willson},
howpublished = {\url{https://huggingface.co/will702/indo-roBERTa-financial-sentiment-v2}},
year = {2026},
note = {Fine-tuned from ihsan31415/indo-roBERTa-financial-sentiment with multi-source data and augmentation},
}
Acknowledgments

