
MiMo-V2.5-ASR
Collection
by Xiaomi, converted to MLX • 6 items • Updated
Current variant: 8bit

This repository is a community MLX conversion of the official XiaomiMiMo/MiMo-V2.5-ASR release for Apple silicon. The original model description below is preserved from the official release, and the MLX-specific material in this page is added as an incremental note for local MLX deployment.
Current MLX usage is documented in the GitHub forks below:
Install the current MLX path:
pip install git+https://github.com/ailuntx/mlx-audio@feat/mimo-v25-asr
Download the MLX checkpoints:
hf download mlx-community/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download mlx-community/MiMo-V2.5-ASR-MLX --local-dir ./models/MiMo-V2.5-ASR-MLX
Run transcription from the helper script in ailuntx/MiMo-V2.5-ASR-MLX:
git clone https://github.com/ailuntx/MiMo-V2.5-ASR-MLX.git
cd MiMo-V2.5-ASR-MLX
python run_mimo_asr_mlx.py \
--model ./models/MiMo-V2.5-ASR-MLX \
--audio path/to/audio.wav
Python:
from mlx_audio.stt import load
model = load("./models/MiMo-V2.5-ASR-MLX")
result = model.generate("path/to/audio.wav", language="en")
print(result.text)
Notes:
mlx-community/MiMo-V2.5-ASR-MLX resolves mlx-community/MiMo-Audio-Tokenizer through mlx_manifest.json.ailuntx/mlx-audio.mlx-audio and mlx-audio-swift.MiMo-V2.5-ASR is a state-of-the-art end-to-end automatic speech recognition (ASR) model developed by the Xiaomi MiMo team. It is built to deliver accurate and robust transcription across Mandarin Chinese and English, multiple Chinese dialects, code-switched speech, song lyrics, knowledge-intensive content, noisy acoustic environments, and multi-speaker conversations. MiMo-V2.5-ASR achieves state-of-the-art results on a wide range of public benchmarks.
Automatic speech recognition systems are expected to faithfully transcribe speech signals that originate from diverse languages, dialects, accents, and domains, and that are captured under a wide variety of acoustic conditions. While conventional end-to-end models perform well on in-domain data, they still fall short of real-world requirements in challenging scenarios such as dialect mixing, code-switching, knowledge-intensive content, noisy environments, and multi-speaker conversations. Therefore, we present MiMo-V2.5-ASR, an end-to-end speech recognition model developed by the Xiaomi MiMo team. Through large-scale mid-training, high-quality supervised fine-tuning, and a novel reinforcement-learning algorithm, MiMo-V2.5-ASR achieves systematic improvements along the following dimensions:
MiMo-V2.5-ASR has been evaluated across a broad set of benchmarks spanning standard Mandarin and English, Chinese dialects, lyric recognition, and internal business scenarios. The chart below summarizes the average performance of MiMo-V2.5-ASR across these scenarios.
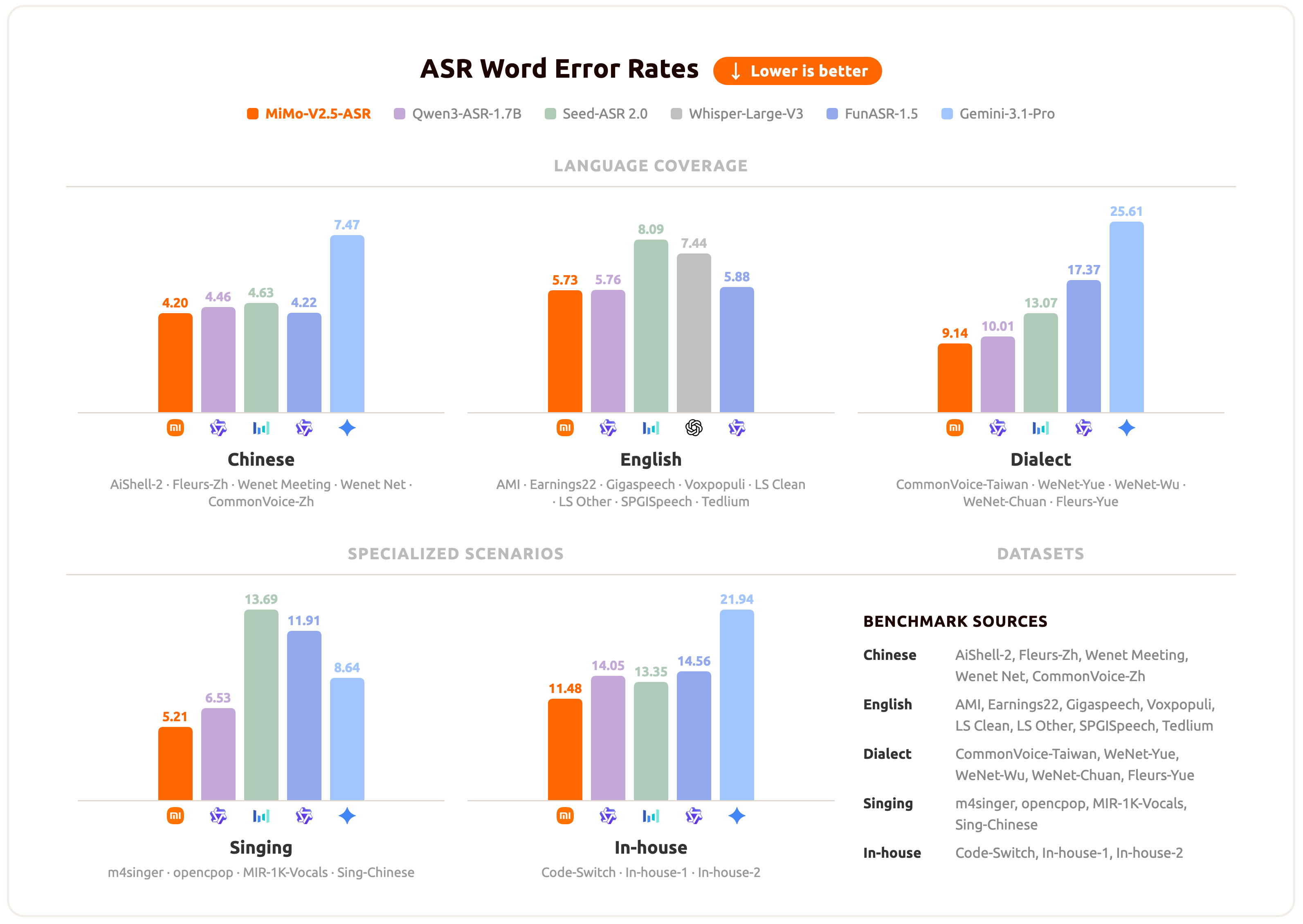
For per-benchmark numbers and specific qualitative cases, please refer to the official blog.
| Models | 🤗 Hugging Face |
|---|---|
| MiMo-Audio-Tokenizer | XiaomiMiMo/MiMo-Audio-Tokenizer |
| MiMo-V2.5-ASR | XiaomiMiMo/MiMo-V2.5-ASR |
pip install huggingface-hub
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download XiaomiMiMo/MiMo-V2.5-ASR --local-dir ./models/MiMo-V2.5-ASR
The following repositories are MLX conversions derived from the official release:
| Variant | Precision | Size | Local smoke time | Smoke result |
|---|---|---|---|---|
MiMo-V2.5-ASR-MLX |
4bit | 4.2 GB | 0.88 s | Intention. |
MiMo-V2.5-ASR-MLX-4bit |
4bit | 4.2 GB | 0.88 s | Intention. |
MiMo-V2.5-ASR-MLX-8bit |
8bit | 8.0 GB | 10.80 s | Intention. |
MiMo-V2.5-ASR-MLX-bf16 |
bf16 | 15 GB | - | dense reference export |
MiMo-V2.5-ASR-MLX-fp32 |
fp32 | 30 GB | - | dense reference export |
MLX conversion notes:
XiaomiMiMo/MiMo-V2.5-ASRmlx-community/MiMo-Audio-Tokenizer2026-05-12mlx-audio and mlx-audio-swiftMiMo-V2.5-ASR-MLXExample downloads:
hf download mlx-community/MiMo-V2.5-ASR-MLX --local-dir ./models/MiMo-V2.5-ASR-MLX
hf download mlx-community/MiMo-V2.5-ASR-MLX-8bit --local-dir ./models/MiMo-V2.5-ASR-MLX-8bit
Local smoke validation was run with mlx-audio and mlx-audio-swift.
intention.wav -> Intention.conversational_a.wav -> expected coffee / Kaldi paragraphThe following section is preserved from the official project and describes the original Python/CUDA workflow.
Spin up the MiMo-V2.5-ASR demo in minutes with the built-in Gradio app.
git clone https://github.com/XiaomiMiMo/MiMo-V2.5-ASR.git
cd MiMo-V2.5-ASR-MLX
pip install -r requirements.txt
pip install flash-attn==2.7.4.post1
If the compilation of flash-attn takes too long, you can download the precompiled wheel and install it manually:
pip install /path/to/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
python run_mimo_asr.py
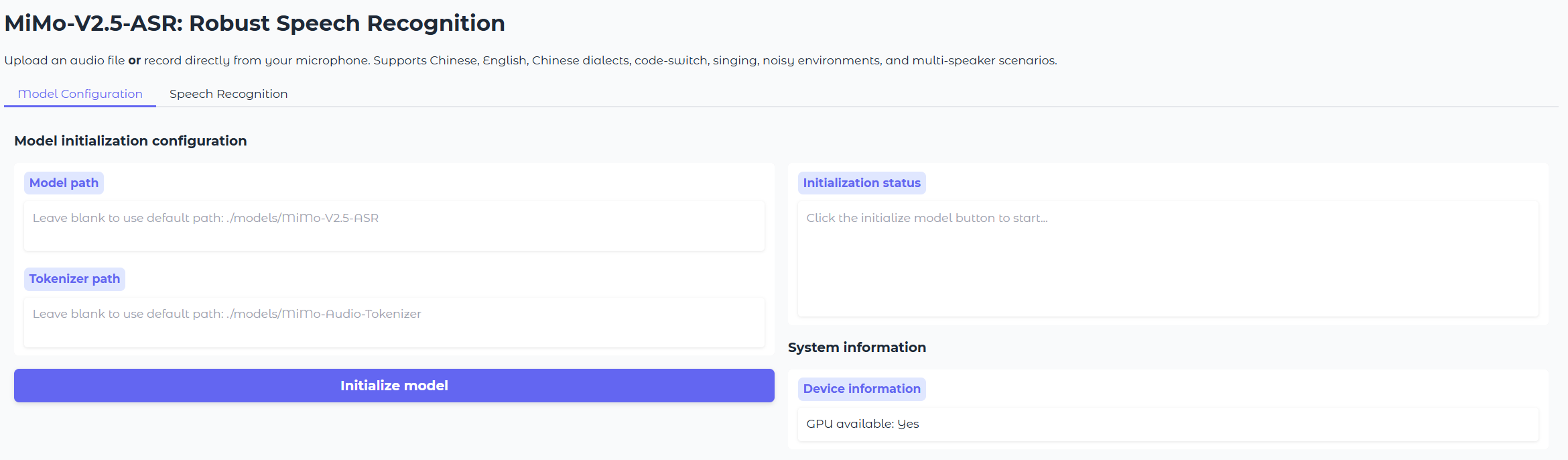
This launches a local Gradio interface for MiMo-V2.5-ASR. You can:
asr_sft() interface under the hood.To load the model and tokenizer automatically at startup, pass their paths on the command line:
python run_mimo_asr.py \
--model-path ./models/MiMo-V2.5-ASR \
--tokenizer-path ./models/MiMo-Audio-Tokenizer
Otherwise, enter the local paths for MiMo-Audio-Tokenizer and MiMo-V2.5-ASR in the Model Configuration tab, then start transcribing.
The following API example is preserved from the official project.
Basic usage with the asr_sft interface:
from src.mimo_audio.mimo_audio import MimoAudio
model = MimoAudio(
model_path="./models/MiMo-V2.5-ASR",
tokenizer_path="./models/MiMo-Audio-Tokenizer",
)
# Automatic language detection (recommended for code-switching)
text = model.asr_sft("path/to/audio.wav")
print(text)
# With explicit language tag
text_zh = model.asr_sft("path/to/audio.wav", audio_tag="<chinese>")
text_en = model.asr_sft("path/to/audio.wav", audio_tag="<english>")
@misc{coreteam2026mimov25asr,
title={MiMo-V2.5-ASR: Robust Speech Recognition Across Languages, Dialects, and Complex Acoustic Scenarios},
author={LLM-Core-Team Xiaomi},
year={2026},
url={https://github.com/XiaomiMiMo/MiMo-V2.5-ASR},
}
Please contact mimo@xiaomi.com or open an issue in the official project if you have questions about the original model.
8-bit
Base model
XiaomiMiMo/MiMo-V2.5-ASR